요즘 회사 사내 교육을 듣고 있는데 #파이썬 ( #python ) 강사분들이 강의 시 주로 #구글 의 #colab 환경에서 강의를 진행하기에 저도 investing.com에서 #크롤링(#crawling)해왔던 데이터를 기반으로 일단 기초 데이터 분석을 진행해보았습니다.
1) 파이썬 라이브러리 import
## 0.환경준비 ### 01.Import import pandas as pd import numpy as np from pandas import Series, DataFrame import matplotlib.pyplot as plt # 시계열 시각화뭐 파이썬 하시는 분은 기본이니 여기는 빠르게 넘어가고요.
2) 예제 파일 하나(AGG) 파일 읽어오기
# 구글 드라이브 마운틴 from google.colab import drive drive.mount("/content/drive") # 데이터 읽어오기(예제) # 일단 예제로 하나를 해보고요. df_agg = pd.read_csv("./etf_data/etf_us_AGG_bond.csv") df_agg.head()일단 잘 되는지 보기 위해 ETF 시세 데이터 중 AGG 데이터를 가져와서 뿌려봅니다.
저의 파일은 colab에 etf_data 폴더에 아래와 같이 있어서 제대로 불러지는지 테스트 코딩해봅니다.
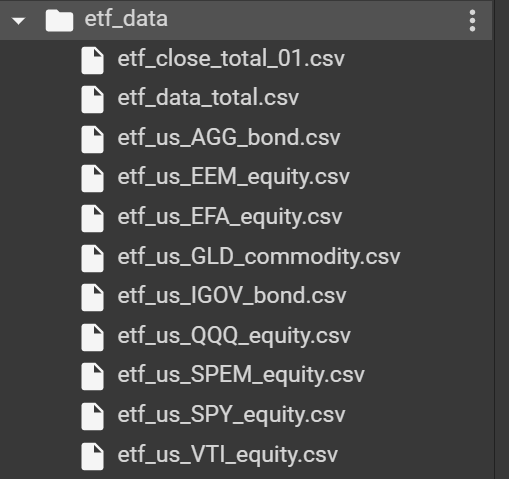
Date Open High Low Close Volume Currency Exchange name symbol 0 2010-01-04 103.27 103.41 103.15 103.31 987879 USD NYSE iShares Core US Aggregate Bond AGG 1 2010-01-05 103.62 103.82 103.52 103.78 500418 USD NYSE iShares Core US Aggregate Bond AGG 2 2010-01-06 103.82 103.82 103.41 103.72 714211 USD NYSE iShares Core US Aggregate Bond AGG 3 2010-01-07 103.66 103.71 103.47 103.60 705695 USD NYSE iShares Core US Aggregate Bond AGG 4 2010-01-08 103.87 103.87 103.54 103.66 412240 USD NYSE iShares Core US Aggregate Bond AGG3) 이제 9개 파일의 데이터를 일단 다 가져와서 merge합니다.
# ETF TICKER 이름들 list etf_tickers = ['AGG', 'EEM', 'EFA', 'GLD', 'IGOV', 'QQQ', 'SPEM', 'SPY', 'VTI'] # ETF 자산구분 etf_types =['bond', 'equity', 'equity', 'commodity', 'bond', 'equity', 'equity', 'equity', 'equity'] df = {} data = DataFrame() for i in range(0,8) : df[i] = pd.read_csv("./etf_data/etf_us_{}_{}.csv".format(etf_tickers[i],etf_types[i]),index_col='Date') if i == 0 : data = df[i] else : data= pd.merge(data, df[i], on= 'Date', how = 'left')4) 없는 값은 이전 종가를 그대로 가져간다고 봄
# 없는 값은 휴일로 간주하고 이전 값으로 채우는 방식으로 # nan값을 처리함 data = data.fillna(method='ffill')#bfill data.to_csv("./etf_data/etf_data_total.csv")그래서 전체 데이타를 파일에 저장했습니다.
5) 이제 전체 종가를 data2데이타프레임에 저장하기
# ETF TICKER 이름들 list etf_tickers = ['AGG', 'EEM', 'EFA', 'GLD', 'IGOV', 'QQQ', 'SPEM', 'SPY', 'VTI'] # ETF 자산구분 etf_types =['bond', 'equity', 'equity', 'commodity', 'bond', 'equity', 'equity', 'equity', 'equity'] df = {} data2 = DataFrame() for i in range(0,8) : df[i] = pd.read_csv("./etf_data/etf_us_{}_{}.csv".format(etf_tickers[i],etf_types[i]),index_col='Date') data2[etf_tickers[i]]= df[i]['Close'] print(data2.head()) data2.isnull().sum() # 없는 값은 휴일로 간주하고 이전 값으로 채우는 방식으로 # nan값을 처리함 data2 = data2.fillna(method='ffill')#bfill data2.to_csv("./etf_data/etf_close_total_01.csv")6) 데이터 시각화
data_p = data2.plot(title='ETF Close Charts') fig = data_p.get_figure() fig.set_size_inches(13.5,9)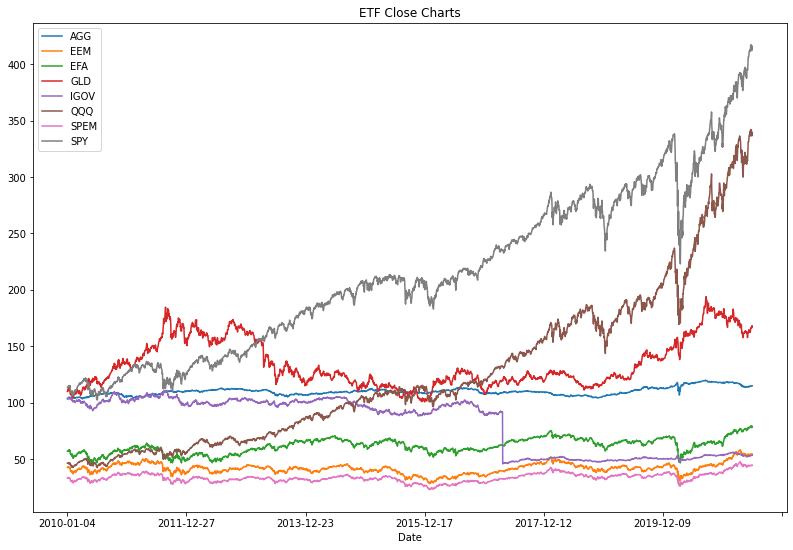
일단 오늘은 2010년 1월 4일부터 2021년 4월 22일(데이터 가져온 날짜)의 데이터를 시각화하는데까지만 하고 책을 보렵니다.
기본적으로 네이버 블로그를 버릴 수는 없어서 네이버 블로그에는 이제는 책리뷰,서평과 농장 생활을 올리고 보다 전문적인 투자분석 및 ETF를 통한 자산배분전략에 대한 이야기는 tistory에 올리도록 하렵니다.
이전 데이터가 보고싶으신 분은 제 네이버 블로그 참고하세요
https://blog.naver.com/dayhyub/222299816483
[해외주식 ETF 데이터 수집] investing.com에서 python 웹크롤링하기 #1
그동안 해보고 싶었던 일인데 책을 읽는 일이 더 좋아서 안 하고 있었습니다. 그래도 드디어 오늘부터 다시...
blog.naver.com
